
前回の記事ではクロール&スクレイピングのフレームワークとしてPython上で稼働するScrapyの環境構築を行いました。
今回はいよいよScrapyでプロジェクトを作成し、サンプルのクローラーを作っていきたいと思います。Scrapyのお作法に乗っ取ることで、プログラミング経験がそれほど豊富でない人でも簡単にクローラーを作ることが出来ます。
1.Scrapyプロジェクトを作成する
まずは作業するプロジェクトを作成します。
コマンド:
scrapy startproject [PJ名]
実行例:
[apl1@44007 ~]$ scrapy startproject samplepj
New Scrapy project ‘samplepj’, using template directory ‘/usr/lib64/python2.7/site-packages/scrapy/templates/project’, created in:
/home/apl1/samplepj
You can start your first spider with:
cd samplepj
scrapy genspider example example.com
[apl1@44007 ~]$
プロジェクトが作成されると、入力したプロジェクト名のディレクトリが作成され配下に以下のようなファイルが作成されます。
[apl1@44007 ~]$ ls -lR
.:
total 4
drwxr-xr-x 3 apl1 apl1 4096 Oct 27 11:51 samplepj
./samplepj:
total 8
drwxr-xr-x 3 apl1 apl1 4096 Oct 27 11:51 samplepj
-rw-r–r– 1 apl1 apl1 260 Oct 27 11:51 scrapy.cfg
./samplepj/samplepj:
total 20
-rw-r–r– 1 apl1 apl1 0 Oct 27 07:57 __init__.py
-rw-rw-r– 1 apl1 apl1 287 Oct 27 11:51 items.py
-rw-rw-r– 1 apl1 apl1 1906 Oct 27 11:51 middlewares.py
-rw-rw-r– 1 apl1 apl1 288 Oct 27 11:51 pipelines.py
-rw-rw-r– 1 apl1 apl1 3148 Oct 27 11:51 settings.py
drwxr-xr-x 2 apl1 apl1 4096 Oct 27 07:57 spiders
./samplepj/samplepj/spiders:
total 4
-rw-r–r– 1 apl1 apl1 161 Oct 27 07:57 __init__.py
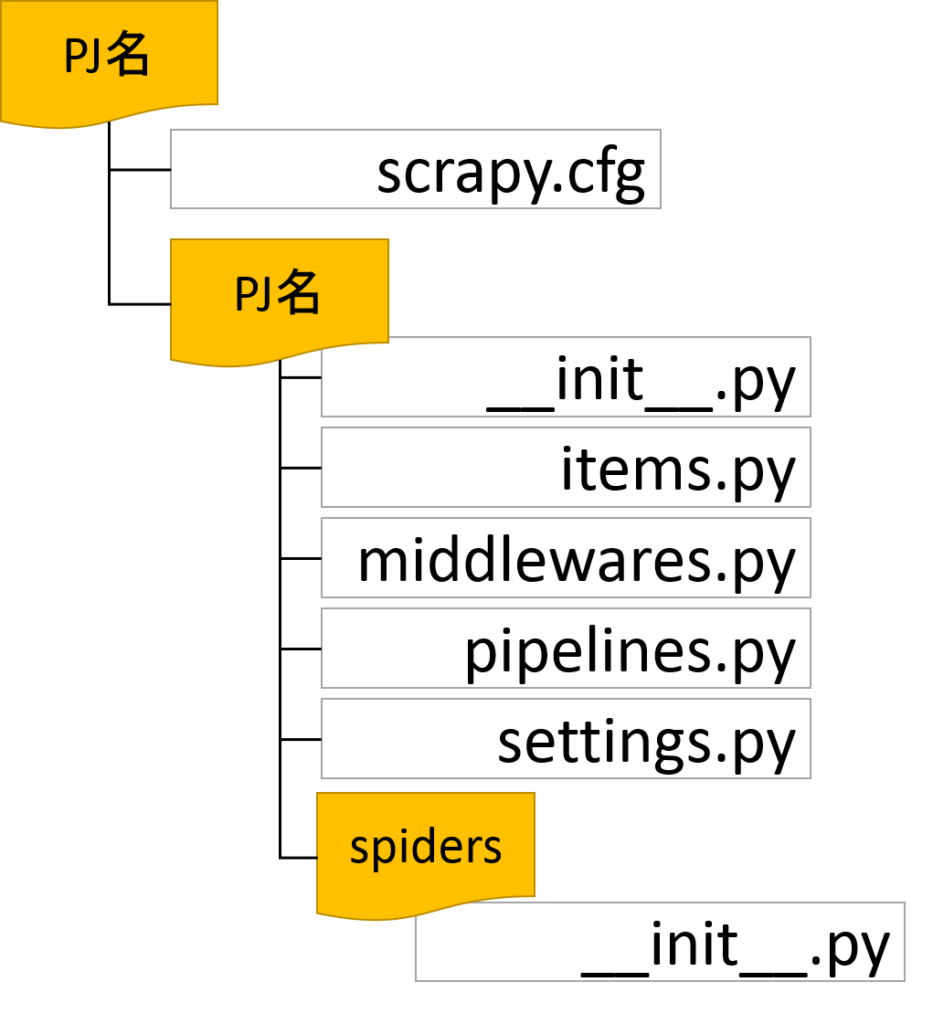
図. ディレクトリ構造
これらが、Scrapyにおける情報取得のための設定や、クローラーインスタンスである「Spider」の動作を定義するファイルです。

ちなみに、Spiderの名前の由来はインターネット上に蜘蛛の巣のように張り巡らされたリンクを辿って情報を収集してくることからだそうです。
2.共通設定ファイルの修正
さて、Scrapyプロジェクトを作成したらまずやっておきたいことは、共通設定ファイルの必要事項を修正することです。特に、DOWNLOAD_DELAYという項目は、最初に必ず設定しておいたほうが良いでしょう。
この項目はSpiderがサイトを巡回する際の待ち時間を設定する項目で、デフォルトでは待ち時間無しでガンガン巡回する設定になっています。このまま実行すると、訪問先のサイトに過度の負荷をかけ、最悪の場合、サイバー攻撃扱いされることにもつながるため最初に設定しておくほうが無難です。
設定は、settings.pyのDOWNLOAD_DELAYに、間隔を秒単位で指定します。
DOWNLOAD_DELAY = [巡回時の待ち時間(秒)]
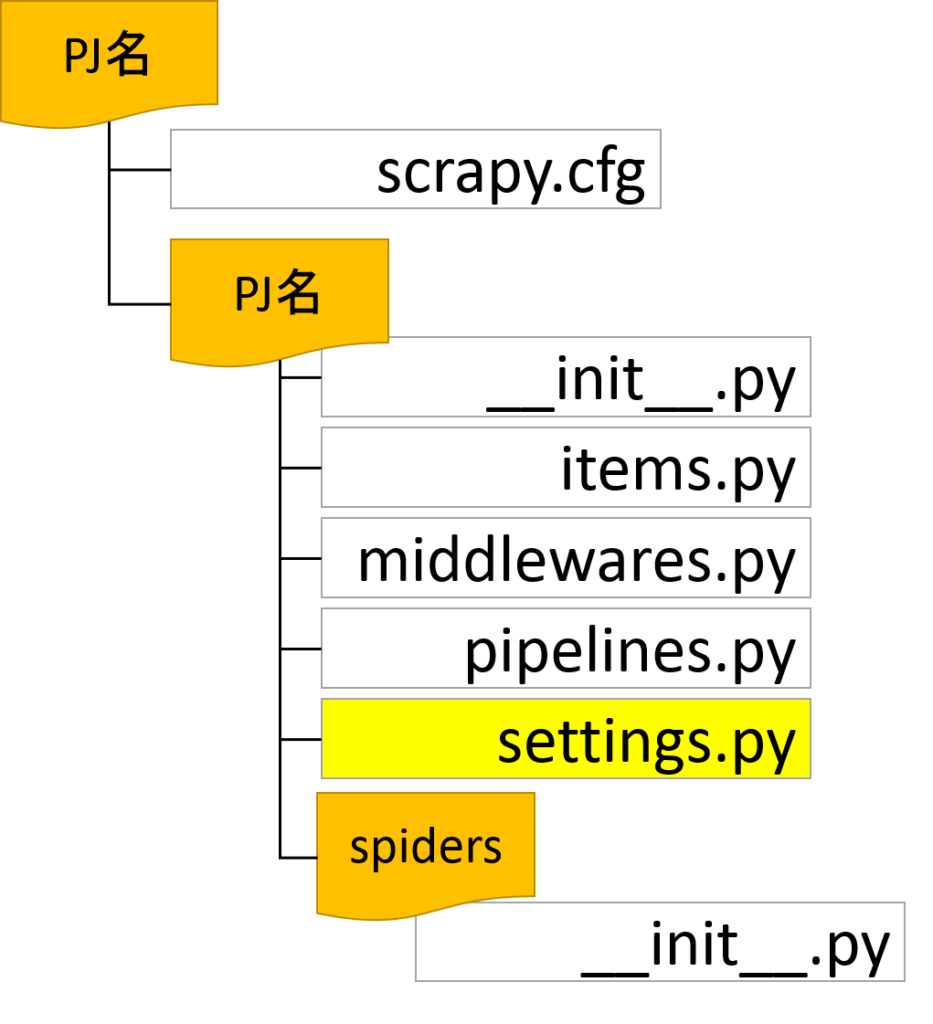
修正例
5秒間隔に変更。
[apl1@44007 samplepj]$ cat settings.py
# -*- coding: utf-8 -*-
# Scrapy settings for samplepj project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
BOT_NAME = ‘samplepj’
SPIDER_MODULES = [‘samplepj.spiders’]
NEWSPIDER_MODULE = ‘samplepj.spiders’
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = ‘samplepj (+http://www.yourdomain.com)’
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 5
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# ‘Accept’: ‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8’,
# ‘Accept-Language’: ‘en’,
#}
# Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# ‘samplepj.middlewares.SamplepjSpiderMiddleware’: 543,
#}
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# ‘samplepj.middlewares.MyCustomDownloaderMiddleware’: 543,
#}
# Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# ‘scrapy.extensions.telnet.TelnetConsole’: None,
#}
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# ‘samplepj.pipelines.SamplepjPipeline’: 300,
#}
# Enable and configure the AutoThrottle extension (disabled by default)
# See http://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = ‘httpcache’
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = ‘scrapy.extensions.httpcache.FilesystemCacheStorage’
[apl1@44007 samplepj]$
[adsense]
3.Itemの定義
Itemは、クローラーが取得してきた情報を格納するためのオブジェクトです。取得してきた情報の容れ物、と考えればよいでしょう。
Itemの定義はitems.pyを編集します。
編集例
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class SamplepjItem(scrapy.Item):
# define the fields for your item here like:
contents = scrapy.Field()
title = scrapy.Field()
4.Spiderの作成
いよいよクローラー本体であるSpiderを作成します。Scrapyではコマンドを実行することで、雛形として標準スパイダーを作成することが出来ます。
コマンド:
scrapy genspider [spider名] [対象ドメイン]
実行例:
scrapy genspider sample01 saikyouse.com
Created spider ‘sample01’ using template ‘basic’ in module:
samplepj.spiders.sample01
[apl1@44007 samplepj]$
コマンドが正常に完了すると、spidersディレクトリ配下に[spider名].pyというファイルが作成されます。
/home/apl1/samplepj/samplepj/spiders
[apl1@44007 spiders]$ ls
__init__.py __init__.pyc sample01.py
[apl1@44007 spiders]$
作成されたファイルを修正して、巡回対象のサイトを記載していきます。今回は、本サイトの月別カテゴリからタイトルを取得してくるというSpiderを作ってみましょう。
要件:
http://saikyouse.com/2017/10/の各記事のタイトルとブログ記事の冒頭部分を取得する。
Spider編集例
sample01.py
# -*- coding: utf-8 -*-
import scrapy
from samplepj.items import SamplepjItem
class Sample01Spider(scrapy.Spider):
name = ‘sample01’
allowed_domains = [‘saikyouse.com’]
start_urls = [‘http://saikyouse.com/2017/09/’]
def parse(self, response):
for val in response.css(“dl.clearfix”):
article = SamplepjItem()
article[‘contents’] = val.css(“div.smanone2 > p::text”).extract_first()
article[‘title’] = val.css(“dd > h3 > a::text”).extract_first()
yield article
[adsense]
5.Spiderの実行
Spiderの定義ファイルを作成したら、早速実行してみましょう。
コマンド:
scrapy crawl [Spider名]
実行例:
scrapy crawl sample01
[apl1@44007 samplepj]$ scrapy crawl sample01
2017-10-29 10:35:00 [scrapy.utils.log] INFO: Scrapy 1.4.0 started (bot: samplepj)
2017-10-29 10:35:00 [scrapy.utils.log] INFO: Overridden settings: {‘NEWSPIDER_MODULE’: ‘samplepj.spiders’, ‘ROBOTSTXT_OBEY’: True, ‘SPIDER_M
ODULES’: [‘samplepj.spiders’], ‘FEED_EXPORT_ENCODING’: ‘UTF-8’, ‘BOT_NAME’: ‘samplepj’}
2017-10-29 10:35:00 [scrapy.middleware] INFO: Enabled extensions:
[‘scrapy.extensions.memusage.MemoryUsage’,
‘scrapy.extensions.logstats.LogStats’,
‘scrapy.extensions.telnet.TelnetConsole’,
‘scrapy.extensions.corestats.CoreStats’]
2017-10-29 10:35:00 [scrapy.middleware] INFO: Enabled downloader middlewares:
[‘scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware’,
‘scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware’,
‘scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware’,
‘scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware’,
‘scrapy.downloadermiddlewares.useragent.UserAgentMiddleware’,
‘scrapy.downloadermiddlewares.retry.RetryMiddleware’,
‘scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware’,
‘scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware’,
‘scrapy.downloadermiddlewares.redirect.RedirectMiddleware’,
‘scrapy.downloadermiddlewares.cookies.CookiesMiddleware’,
‘scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware’,
‘scrapy.downloadermiddlewares.stats.DownloaderStats’]
2017-10-29 10:35:00 [scrapy.middleware] INFO: Enabled spider middlewares:
[‘scrapy.spidermiddlewares.httperror.HttpErrorMiddleware’,
‘scrapy.spidermiddlewares.offsite.OffsiteMiddleware’,
‘scrapy.spidermiddlewares.referer.RefererMiddleware’,
‘scrapy.spidermiddlewares.urllength.UrlLengthMiddleware’,
‘scrapy.spidermiddlewares.depth.DepthMiddleware’]
2017-10-29 10:35:00 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2017-10-29 10:35:00 [scrapy.core.engine] INFO: Spider opened
2017-10-29 10:35:00 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2017-10-29 10:35:00 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2017-10-29 10:35:01 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://saikyouse.com/robots.txt> (referer: None)
2017-10-29 10:35:01 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://saikyouse.com/2017/09/> (referer: None)
2017-10-29 10:35:01 [scrapy.core.scraper] DEBUG: Scraped from <200 http://saikyouse.com/2017/09/>
{‘contents’: u’\u672c\u7a3f\u3067\u306f\u300c\u81ea\u5206\u3068\u4ed6\u4eba\u300d\u3092\u3069\u306e\u3088\u3046\u306b\u898b\u3064\u3081\u308
b\u304b\u3068\u8a00\u3046\u3053\u3068\u306b\u3064\u3044\u3066\u8003\u3048\u3066\u307f\u305f\u3044\u3002 SE\u306e\u4ed5\u4e8b\u306f\u591a\u30
4f\u306e\u95a2\u4fc2\u8005\u3068\u69d8\u3005\u306a\u7acb\u5834\u3067\u63a5\u3059\u308b\u5fc5\u8981\u306e\u3042\u308b\u3001\u4eba\u9593\u95a2
\u4fc2\u306e\u69cb\u7bc9\u3068\u7dad\u6301\u304c\u975e\u5e38\u306b\u96e3\u3057\u3044\u4ed5\u4e8b\u3060\u3002\u305d\u306e\u4e2d\u3067\u4eba\u
9593\u95a2\u4fc2\u304b\u3089\u6765\u308b … ‘,
‘title’: u’\n\t\t\t\t\t\t\u81ea\u5df1\u8a8d\u8b58\u306e\u30d0\u30e9\u30f3\u30b9\u3092\u3068\u3063\u3066\u5145\u5b9f\u3057\u305f\u4eba\u751f
\u3092\u9001\u308b\u305f\u3081\u306e\u8003\u3048\u65b9\t\t\t\t\t’}
2017-10-29 10:35:01 [scrapy.core.scraper] DEBUG: Scraped from <200 http://saikyouse.com/2017/09/>
{‘contents’: u’\xa0 \u672c\u7a3f\u3067\u306f\u30b7\u30fc\u30b1\u30f3\u30b9\u56f3\u306b\u3064\u3044\u3066\u3001
(中略)
2017-10-29 10:35:01 [scrapy.core.scraper] DEBUG: Scraped from <200 http://saikyouse.com/2017/09/>
{‘contents’: None, ‘title’: None}
2017-10-29 10:35:01 [scrapy.core.engine] INFO: Closing spider (finished)
2017-10-29 10:35:01 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{‘downloader/request_bytes’: 440,
‘downloader/request_count’: 2,
‘downloader/request_method_count/GET’: 2,
‘downloader/response_bytes’: 9306,
‘downloader/response_count’: 2,
‘downloader/response_status_count/200’: 2,
‘finish_reason’: ‘finished’,
‘finish_time’: datetime.datetime(2017, 10, 29, 8, 35, 1, 867954),
‘item_scraped_count’: 15,
‘log_count/DEBUG’: 18,
‘log_count/INFO’: 7,
‘memusage/max’: 45780992,
‘memusage/startup’: 45776896,
‘response_received_count’: 2,
‘scheduler/dequeued’: 1,
‘scheduler/dequeued/memory’: 1,
‘scheduler/enqueued’: 1,
‘scheduler/enqueued/memory’: 1,
‘start_time’: datetime.datetime(2017, 10, 29, 8, 35, 0, 335049)}
2017-10-29 10:35:01 [scrapy.core.engine] INFO: Spider closed (finished)
[apl1@44007 samplepj]$
デフォルトでは出力結果のJSONはUnicodeで返ってくるため、日本語が含まれていると上記のようにエンコードされてしまいます。出力結果を日本語で表示したい場合はsettings.pyの以下の項目を設定すると良いそうです。
FEED_EXPORT_ENCODING=’utf-8′
また、日本語を表示したい場合にはLinuxの環境設定自体も事前に日本語に対応しておく必要があります。
6.結果のファイル出力
出力結果はデフォルトではJSON形式で返ってきますが、CSVなどに変更することも可能です。
また、-oオプションを利用することでテキストファイルに出力することが出来ます。
コマンド:
scrapy crawl sample01 -o [ファイル名]
実行例:
scrapy crawl sample01 -o output.csv
(出力ファイル内容)
[apl1@44007 samplepj]$ head output.csvcontents,title
本稿では「自分と他人」をどのように見つめるかと言うことについて考えてみたい。 SEの仕事は多くの関係者と様々な立場で接する必要のある、人間関係の構築と維持が非常に難しい仕事だ。その中で人間関係から来る … ,”自己認識のバランスをとって充実した人生を送るための考え方”
本稿ではシーケンス図について、2分で読めるボリュームに要約して紹介する。 1.シーケンス図とは シーケンス図とは、プログラム間(クラスやオブジェ … ,”シーケンス図~2分でわかるSE用語集~”
皆さんは働いて得たお金をどのように使っているだろうか。自分の趣味やストレス発散に使っているという人もいれば、資格取得やセミナー受講など、仕事の準備、すなわち自己投資に使っているという人もいるだろう。 … ,”SEのための自己投資のすすめ”
現役のSEに、SEの仕事についてインタビューするこのシリーズ、10人目は大手ソフトウェアベンダーで流通業界に携わっている勤続25年のベテラン男性SEのKさんです。 Kさんの … ,”これからはIoT!勤続25年で挑戦を続けるベテランSEの熱き想い~SEインタビューNo.11~”
(以下略)
想定通り、月別アーカイブのページから各記事のタイトルと内容の冒頭部分が取得できていますね。
これで、簡単な構造のサイトであれば情報を取ってくることができるようになりました。次回以降は取得したデータの活用に焦点をあててみたいと思います。













コメントを残す